The Ultimate Guide to Top 10 Data Science Tools in 2024
Growing interest in data science has driven a growth in data science tools development. There are 2 classes of data science tools emerging:
- Self-service tools for those with technical expertise (programming skills and understanding of statistics and computer science)
- Tools for business users that automate commonly used analysis
Learn the most popular data science tools for techies
Becoming data scientist is hard. In any hard task, focus is critical. As a data scientist, Python should probably be the first tool you should master.
Kaggle, the community for data science competitions, publishes surveys of data scientist such as their “2022 Data Science and Machine Learning Survey”. 1 Below, you can find the most popular tools from their survey:
| Data science tool | % of respondents using the tool |
|---|---|
| Python | 87.6 |
| SQL | 43.1 |
| C++ | 22.2 |
| R | 21.4 |
| Java | 19.1 |
| C | 18.9 |
| JavaScript | 17.4 |
| MATLAB | 11.8 |
| Other | 10.3 |
| Bash | 8.9 |
| None | 1.3 |
| Julia | 1.2 |
| Swift | 1 |
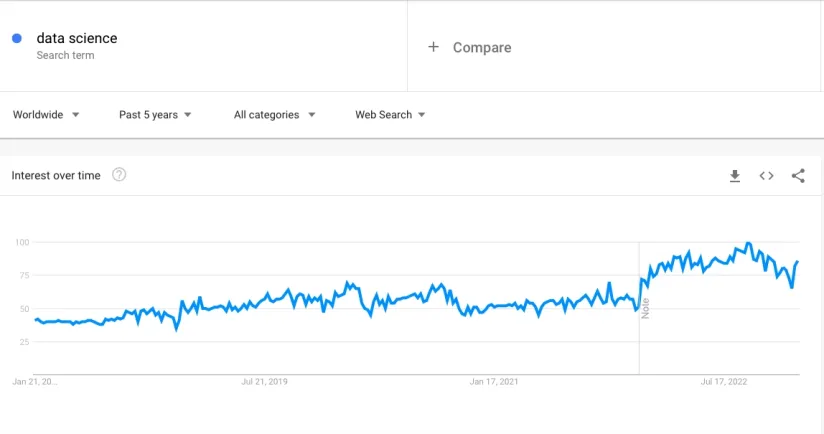
Python is still widely regarded as the first data science language users should learn. We keep our previous year’s outlook that Python’s popularity will continue to grow. According to the survey, 81% of respondents believe Python should be the first language they learn (see Figure 1).
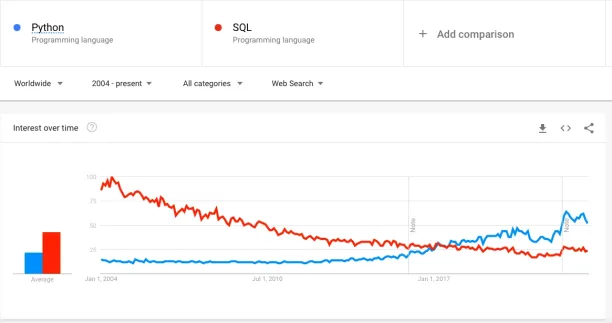
Moreover, per Google Trends, Python has been in the lead over SQL ever since 2016 (See Figure 2).
Finally, although it is clear that Python is the most popular tool among data scientist, there’s a whole ecosystem of data science tools which is summarized nicely in the picture below (see Figure 3).
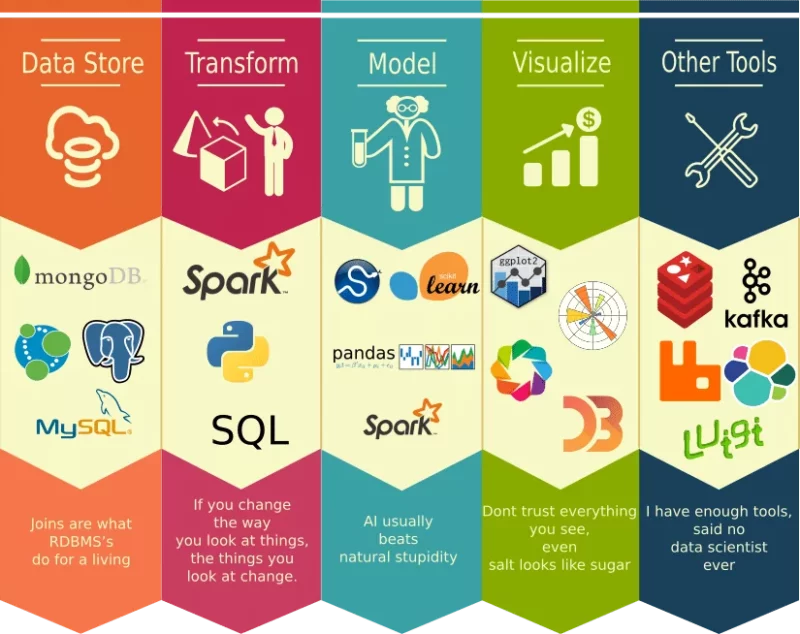
Understand the data science tools landscape
There are 2 important categories of data science tools: open source vs proprietary code and no/low code vs code.
Most of these tools are open source, however, there are providers like DataRobot or Paxata that use proprietary code. However, even providers that rely on proprietary software open source either some parts of their solution or launch initiatives like DataRobot’s Open Source Model Infrastructure aimed to attract data scientists that would like to work on an open-source platform. 2
While platforms like Tensorflow cater to data scientists that prefer writing code, platforms like DataRobot help business users develop machine learning applications.
Identify the alternatives to building your own models
While companies can build their own data science solutions, there are other approaches as well.
You can rely on the wisdom of crowds to build cost-effective data science models through data science competition platforms.
You can also check our articles on AI consulting and data science consulting.
10 Data Science Tools Everyone Needs to Know
The following list contains the top 10 data science tools which we have compiled. Note that the list is ordered in terms of the tools’ popularity and company sizes.
1. Tensorflow
Focused on deep learning and launched by Google, Tensorflow has 164k stars on GitHub. 3 It’s written in C++ and Python. Its capabilities include ML model building either on-premise, on the cloud, in-browser, or on-model.
2. PyTorch
PyTorch is an open-source, built-in Python that has ~55k stars on GitHub, and is widely used by machine learning teams.4
3. Alteryx
Founded in 2015 by MIT data science researchers, Alteryx is a proprietary software platform with 2.4k employees.5
It has made a significant part of its software open source. Its most popular open-source tool, “featuretools,” allows for the creation of automated feature engineering and has ~6k stars on GitHub.6
4. DataRobot
DataRobot is proprietary software with a team of ~1.8k employees.7
5. Dataiku
Dataiku is a company with +1,100 employees.8 As they claim, companies around the world leverage their data and AI for use cases such as fraud detection, churn prevention, and predictive maintenance.
6. H2O.ai
H2O is a fully-open source framework with ML and AutoML capabilities for running different algorithms and choosing the optimum one in the process. H2O is supported by a team of ~400.9
7. Trifacta
With a staff of +150 employees 10, Trifacta specializes in interactive cloud platforms that allow for collaborative data-wrangling, data profiling, and the managing of data pipelines. In 2022, Alteryx acquired Trifacta which continues to serve its users under the Alteryx brand.11
8. RapidMiner
RapidMiner is another open-source tool that highlights its ease of use thanks to a self-explanatory drag-and-drop application. It is supported by a team of 100+ employees. 12
9. Lumen Data
Lumen data has a workforce of 52 employees.13, and they provide users with services such as data strategy and architecture, modernization, master data management, and analytics.
10. Qubole
Qubole is a cloud-based service that specializes in data lakes. Users can perform ad-hoc analysis on their data, improve them by leveraging ML models, and efficiently manage data pipelines. Qubole is supported by a team of ~50 employees.14
Tools to speed up data science project
Web Crawlers
Web crawlers are software that collects web data to be leveraged in data science projects such as real-time analytics, training predictive machine learning models, improving natural language processing capabilities, etc.
Some of the popular data science projects based on web crawling are the language models GPT-3 and Google’s LaMDA.
Data extraction tools
Data science projects can slow down when machine learning models require tabular data and such data is embedded in text or images. It is a technical challenge to convert data from such formats to machine-readable data (e.g. tabular data).
Of course, the data science team can program a model to get data from these documents. But sometimes getting data from these sources is just a step in the data science process to create training data. In such cases, data science teams can rely on data extraction tools to convert unstructured data to structured data. Some of these conversions will not be perfect but they can still provide valuable inputs to data science projects.
Further Reading
To learn more on origin of data science or the steps to follow while choosing a data science consultant, you can check out our relevant articles:
- A Complete Guide to Data Mining: Pros, Cons, & Use Cases
- How to Choose Data Science Consultants
- What is a Data Pipeline? Types & Benefits
Though, we covered the whole ecosystem of data science tools, we did not cover all tools. For a more comprehensive list, check out out data driven, prioritized list of data science/machine learning software.
Or if your business is facing a specific problem, we can help you identify partners to build custom AI models for your business:
External Links
- 1. “2022 Data Science and Machine Learning Survey.” Kaggle. Revisited January 17, 2023.
- 2. “Open Source Model Infrastructure.” Data Robot. Revisited January 16, 2023.
- 3. “Tensorflow.” Github. Revisited January 16, 2023.
- 4. “PyTorch.” Github. Revisited January 16, 2023.
- 5. “Alteryx.” LinkedIn. Revisited January 16, 2023.
- 6. “Alteryx.” Github. Revisited January 16, 2023.
- 7. “DataRobot.” LinkedIn. Revisited January 16, 2023.
- 8. “Dataiku.” LinkedIn. Revisited January 16, 2023.
- 9. “H2O.ai “LinkedIn. Revisited January 16, 2023.
- 10. “Trifacta.” LinkedIn. Revisited January 16, 2023.
- 11. “Alteryx closes acquisition for Trifecta.“ Alteryx. February 2022. Revisited January 16, 2023.
- 12. “RapidMiner.” LinkedIn. Revisited January 16, 2023.
- 13. “Lumendata.” LinkedIn. Revisited January 16, 2023.
- 14. Qubole. LinkedIn. Revisited January 16, 2023.

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
BI Governance: 6 Implementation Best Practices in 2024
Pytorch Lightning in '24: What's new, benefits & key features
Top 50 Big Data Statistics in '24: Market Size & Benefits

It seems feature labs joined Alteryx in 2019. Maybe change out feature labs with another?

Thank you, it is updated now. You are right, we are looking over some acquisitions in our lists and articles. We will look into monitoring such activities more closely. In the meanwhile, thank you for improving our research.

can you please share the name of tools in other section in pic? I know Redis, Kafka and Elastic. what are the other 2 logo?
Didn’t get which ones you are referring to but reverse image search can help.
Related research
Data Mining: What is it & Why do businesses need it in 2024?
Comments
Your email address will not be published. All fields are required.