Guide to Optical Character Recognition (OCR) in 2024


Imagine you want to edit a printed document like a book, a magazine article or a printed contract. You need to spend hours to type the document from the beginning and be careful about the mistakes. Or you can use an Optical Character Recognition (OCR) tool to scan the printed document and digitize the whole text.
OCR is a great solution for converting human-to-human communication but falls short when converting more structured documents such as forms that need to be processed by machines.
Human-to-human communication is mostly in the form of free text like the one you are reading now. Such documents are called unstructured data and while they are great for human-to-human communication but they are hard for machines to understand. OCR converts the text in unstructured data into machine readable text so it can be searched and therefore more easily consumed by humans.
To make text easier for machines to understand, companies and governments developed a myriad of forms that structure text into easily recognizable labels. OCR solutions can convert those into machine readable text but that is just the first step. Machines can not act on most text as they do not understand its meaning. Modern deep learning based data capture solutions further process OCR output, converting it into key-value pairs and tables that can be acted on by machines.
What is OCR?
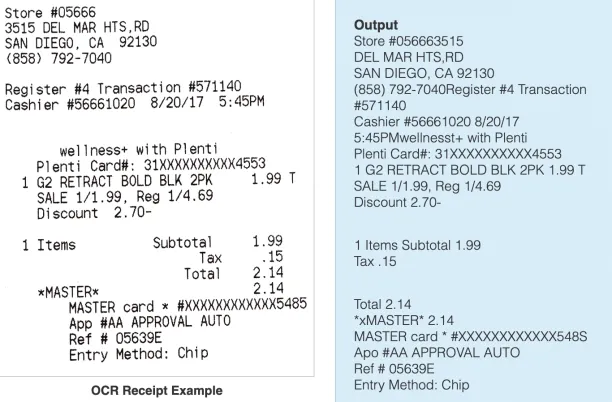
OCR is a specialized technology to perceive the characters of a text within the images like printed books, photos, or scanned documents. It converts text containing images into characters that can be readable by computers to edit, compute, and analyze in the future steps. Below, you can see an example of how OCR digitalizes the text in a receipt.
Popular use cases for OCR technology include digitizing books and other unstructured documents that enable human-human communication. For example, Google translate’s OCR enables users to read in any language:

Why is OCR is no longer implemented stand-alone today in human-machine communication?
While OCR captures text and converts it machine-readable, it only provides unstructured characters. However, forms are designed for human-machine communication so machines can automatically act on the data they receive from humans. Thus, vendors need to process OCR results with machine learning to turn machine-readable data into machine-actionable data.
As explained, OCR is still a foundational technology and its performance is important. These are some of the impediments to its performance:
- The image can be skewed or non-oriented. In these cases, OCR might not recognize the characters because the text isn’t aligned. Thus, OCR software should be able to straighten and de-skew images.
- Colored and varying background patterns might be problematic as they can be reduce text recognition. Fixed backgrounds can improve OCR performance.
- Text in glared or blurry images are hard to read for humans as well machines. Higher image quality leads to higher quality OCR output.
What is data extraction?
Data extraction (document capture) is the process of turning unstructured or semi-structured data (e.g. forms) into structured data (e.g. text documents, emails).
As OCR only recognizes characters from sources, data extraction does more than that. With OCR, companies get characters that have no meaning to machines. However, data extraction includes structuring this data to make it actionable. For example, data extraction automates invoice processing so payments and record keeping can be automated.
Feel free to read our document capture software list learn more about document capture and see the leading document capture vendors.
OCR Use Cases by Industry
Most industries still rely on legacy systems, yet, increasing interest in digitalization makes OCR technology necessary for businesses.
- Banking: OCR can extract data in
- Checks to capture the account information, the handwritten dollar amount and the signature.
- Mortgage applications which contain numerous documents
- Payslips which are one of the best indicators for disposable income
- Insurance: Claims processing can be automated by OCR and supporting technologies
- Legal: Legal firms can digitize all of their printed documents such as affidavits, judgments, filings, statements, wills via OCR.
- Healthcare: OCR can scan reports that contain X-rays, previous diseases, treatments or diagnostics, tests, hospital records, insurance payments.
Customer-facing applications:
- Tourism: OCR can enable guests self check-in by scanning their own passport on the hotel website or app.
- Retail: Thanks to mobile OCR, customers don’t need to worry about losing vouchers. They can scan serial code via phones to redeem their vouchers.
OCR Vendors
OCR is still a foundational technology as today’s AI vendors rely on it to extract data. While choosing an OCR vendor, you should consider the following factors:
- Character recognition accuracy
- User-friendly interface
- Computation speed
- Output file formats (Word, Excel, PDF, etc.)
- Integration with ERP data
- Learning over time
Below you can find a list of OCR vendors including relevant information which are collected from different resources. You can filter the list by focus areas, customers, and solution types.
| Company | Number of Employees on Linkedin | Area of Focus | Vital Customers | Type of Solution |
|---|---|---|---|---|
| ABBYY FineReader | 1001-5000 | Document recognition, data capture, language processing | Dell, Fujitsu, HP, Siemens | Continuously trained ML |
| Datamolino | 11-50 | Bookkeeping automation | Deloitte | Not template based |
| Docparser | 2-10 | Document data extraction | SMEs | Template based |
| DocuPhase | 11-50 | Data capture, bookkeeping automation | Lockheed Martin, Sharp | Template based |
| Google Cloud Vision API | 10000+ | Document recognition, data capture | Chevron, Texas A&M University | Continuously trained ML |
| Grooper | 51-200 | Document recognition, data capture, language processing | Continuously trained ML | |
| Hypatos | 11-50 | Document data extraction, advanced processing | PwC, Deloitte, EY, Schwarz Gruppe | Continuously trained ML |
| Infrrd | 201-500 | Document data extraction | Nokia, GE | Continuously trained ML |
| Instabase | 11-50 | Document data extraction | Continuously trained ML | |
| Klippa | 11-50 | Document recognition, data capture | Endemol | Continuously trained ML |
| Kofax | 1001-5000 | Document data extraction | Readdy | Continuously trained ML |
| Laserfiche | 201-500 | Document data extraction, document management | Continuously trained ML | |
| Microsoft Azure ReadAPI | 10000+ | Document recognition, data capture | Continuously trained ML | |
| PDFelement | 501-1000 | Document data extraction | Hitachi, Deloitte | Template based |
| Rossum | 11-50 | Document data extraction | Bloomberg, IBM, Nvidia | Continuously trained ML |
| Scanbot | 11-50 | Document recognition and data capture | Template based | |
| Veryfi | 11-50 | Document data extraction, bookkeeping automation | Continuously trained ML |
A popular use case of OCR is invoice capture. With the combination of OCR and other AI techniques, companies can easily extract data from invoices. In the invoice capturing process, OCR is used to transfer data from printed invoices to digital systems. As a result, invoices can be automatically processed faster. To read more about invoice capture, you can read our article about it.

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
OCR Benchmark Methodology in 2024
5 Steps to OCR Training Data in 2024
State of OCR in 2024: Is it dead or a solved problem?

Hi,
I’m a student in Germany and got a thesis ‘OCR for medical records digitization with Deep Learning. Can you please help me in it as I will be thankful. Waiting for support.

We published a detailed benchmark publicly. If that didn’t help, I don’t know how else we can help. Feel free to contact us via email: https://research.aimultiple.com/contact-us/

wonderful explanation.
OCR is available in various forms.
iZoe is one such automation company that provides OCR-based tools for your business needs. It provides automation services like web-based accounting software and invoice software for business use.
Related research

Comments
Your email address will not be published. All fields are required.