What is Synthetic Data? Use Cases & Benefits in 2024
Developing successful AI and ML models requires access to large amounts of high-quality data. However, collecting such data is challenging because:
- Many business problems that AI/ML models could solve require access to sensitive customer data such as Personally Identifiable Information (PII) or Personal Health Information (PHI). Collecting and using sensitive data raises privacy concerns and leaves businesses vulnerable to data breaches. For this reason, privacy regulations such as GDPR and CCPA restrict the collection and use of personal data and impose fines on companies that violate them.
- Some types of data are costly to collect, or they are rare. For instance, collecting data representing the variety of real-world road events for an autonomous vehicle may be prohibitively expensive. Bank fraud, on the other hand, is an example of a rare event. Collecting sufficient data to develop ML models to predict fraudulent transactions is challenging because fraudulent transactions are rare.
As a result, businesses are turning to data-centric approaches to AI/ML development, including synthetic data to solve these problems.
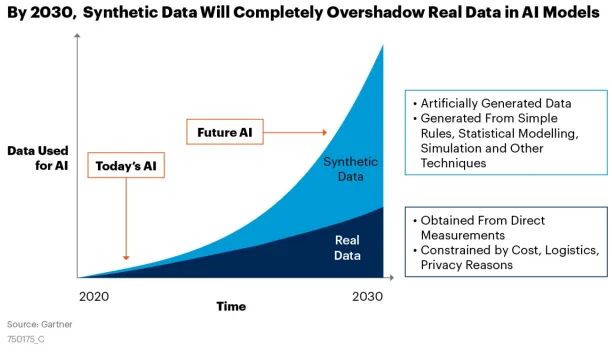
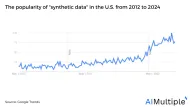
Generating synthetic data is inexpensive compared to collecting large datasets and can support AI/deep learning model development or software testing without compromising customer privacy. It’s estimated that by 2024, 60% of the data used to develop AI and analytics projects will be synthetically generated.
What is synthetic data?
Synthetic data, as the name suggests, is data that is artificially created rather than being generated by actual events. It is often created with the help of algorithms and is used for a wide range of activities, including as test data for new products and tools, for model validation, and in AI model training. Synthetic data is a type of data augmentation.
Why is synthetic data important now?
Synthetic data is important because it can be generated to meet specific needs or conditions that are not available in existing (real) data. This can be useful in numerous cases such as:
- When privacy requirements limit data availability or how it can be used
- Data is needed for testing a product to be released however such data either does not exist or is not available to the testers
- Training data is needed for machine learning algorithms. However, especially in the case of self-driving cars, such data is expensive to generate in real life.
Though synthetic data first started to be used in the ’90s, an abundance of computing power and storage space in the 2010s brought more widespread use of synthetic data.
What are its applications?
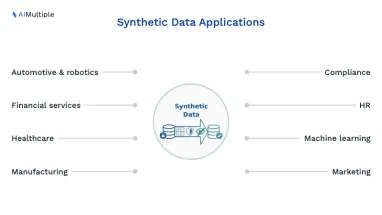
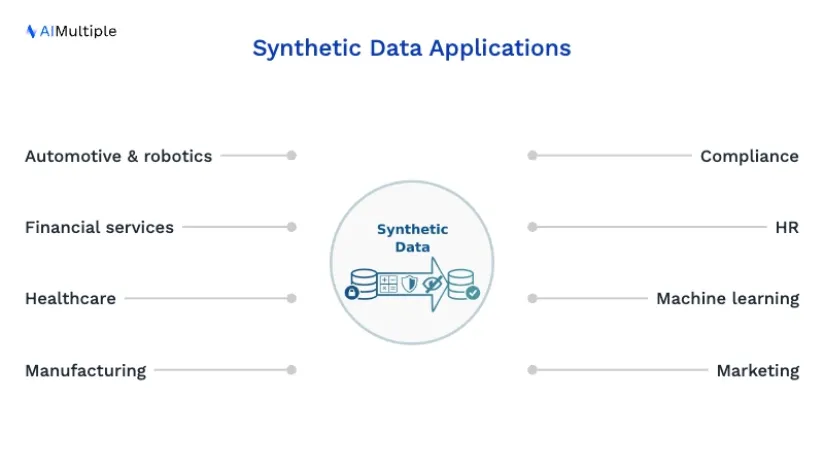
Industries that can benefit from synthetic data:
- Automotive and Robotics
- Financial services
- Healthcare
- Manufacturing
- Security
- Social Media
Business functions that can benefit from synthetic data include:
Synthetic data allows us to continue developing new and innovative products and solutions when the data necessary to do so otherwise wouldn’t be present or available. For a more detailed account, feel free to check our article on synthetic data use cases/applications.
Comparing synthetic and real data performance
Data is used in applications and the most direct measure of data quality is data’s effectiveness when in use. Machine learning is one of the most common use cases for data today. MIT scientists wanted to measure if machine learning models from synthetic data could perform as well as models built from real data. In a 2017 study, they split data scientists into two groups: one using synthetic data and another using real data. 1 70% of the time group using synthetic data was able to produce results on par with the group using real data. This would make synthetic data more advantageous than other privacy-enhancing technologies (PETs) such as data masking and anonymization.
If you want to learn more, feel free to check our infographic on the difference between synthetic data and data masking.
Benefits of synthetic data
Being able to generate data that mimics the real thing may seem like a limitless way to create scenarios for testing and development. While there is much truth to this, it is important to remember that any synthetic models deriving from data can only replicate specific properties of the data, meaning that they’ll ultimately only be able to simulate general trends.
However, synthetic data has several benefits over real data:
- Overcoming real data usage restrictions: Real data may have usage constraints due to privacy rules or other regulations. Synthetic data can replicate all important statistical properties of real data without exposing real data, thereby eliminating the issue.
These benefits demonstrate that the creation and usage of synthetic data will only stand to grow as our data becomes more complex and more closely guarded.
Synthetic data generation / creation 101
When determining the best method for creating synthetic data, it is important to first consider what type of synthetic data you aim to have. There are three broad categories to choose from, each with different benefits and drawbacks:
Fully synthetic: This data does not contain any original data. This means that re-identification of any single unit is almost impossible and all variables are still fully available.
Partially synthetic: Only data that is sensitive is replaced with synthetic data. This requires a heavy dependency on the imputation model. This leads to decreased model dependence but does mean that some disclosure is possible owing to the true values that remain within the dataset.
Hybrid Synthetic: Hybrid synthetic data is derived from both real and synthetic data. While guaranteeing the relationship and integrity between other variables in the dataset, the underlying distribution of original data is investigated and the nearest neighbor of each data point is formed. A near-record in the synthetic data is chosen for each record of real data, and the two are then joined to generate hybrid data.
Two general strategies for building synthetic data include:
Drawing numbers from a distribution: This method works by observing real statistical distributions and reproducing fake data. This can also include the creation of generative models.
Agent-based modeling: To achieve synthetic data in this method, a model is created that explains an observed behavior, and then reproduces random data using the same model. It emphasizes understanding the effects of interactions between agents on a system as a whole.
Deep learning models: Variational autoencoder and generative adversarial network (GAN) models are synthetic data generation techniques that improve data utility by feeding models with more data. Feel free to read in detail how data augmentation and synthetic data support deep learning.
For more, feel free to check out our comprehensive guide on synthetic data generation.
Challenges of Synthetic Data
Though synthetic data has various benefits that can ease data science projects for organizations, it also has limitations:
- Outliers may be missing: Synthetic data can only mimic the real-world data, it is not a replica of it. Therefore, synthetic data may not cover some outliers that the original data has. However, outliers in the data can be more important than regular data points as Nassim Nicholas Taleb explains in depth in his book, the Black Swan.
Machine Learning and Synthetic Data: Building AI
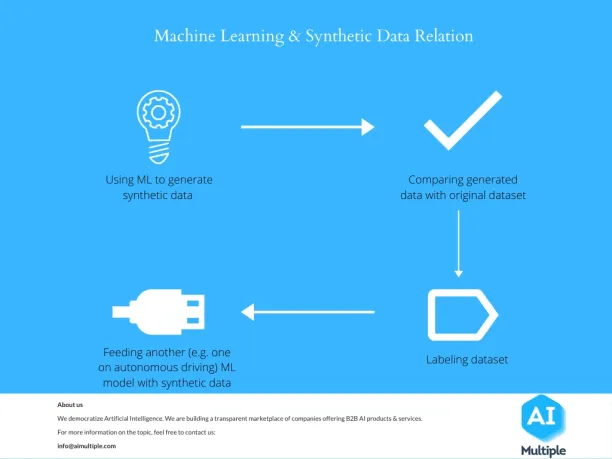
The role of synthetic data in machine learning is increasing rapidly. This is because machine learning algorithms are trained with an incredible amount of data which could be difficult to obtain or generate without synthetic data. It can also play an important role in the creation of algorithms for image recognition and similar tasks that are becoming the baseline for AI.
There are several additional benefits to using synthetic data to aid in the development of machine learning:
- Ease in data production once an initial synthetic model/environment has been established
- Accuracy in labeling that would be expensive or even impossible to obtain by hand
- The flexibility of the synthetic environment to be adjusted as needed to improve the model
- Usability as a substitute for data that contains sensitive information
2 synthetic data use cases that are gaining widespread adoption in their respective machine-learning communities are:
Self-driving simulation
Learning by real life experiments is hard in life and hard for algorithms as well.
- It is especially hard for people that end up getting hit by self-driving cars as in Uber’s deadly crash in Arizona.2 While Uber scales back their Arizona operation, it should probably ramp up their simulations to train their models.
To minimize data generation costs, industry leaders such as Google have been relying on simulations to create millions of hours of synthetic driving data to train their algorithms. 3
For more, feel free to check our article on synthetic data in computer vision.
Generative Adversarial Networks (GAN)
These networks, also called GAN or Generative adversarial neural networks, were introduced by Ian Goodfellow et al. in 2014. These networks are a recent breakthrough in image recognition. They are composed of one discriminator and one generator network. While the generator network generates synthetic images that are as close to reality as possible, the discriminator network aims to identify real images from synthetic ones. Both networks build new nodes and layers to learn to become better at their tasks.
While this method is popular in neural networks used in image recognition, it has uses beyond neural networks. It can be applied to other machine-learning approaches as well. It is generally called Turing learning as a reference to the Turing test. In the Turing test, a human converses with an unseen talker trying to understand whether it is a machine or a human.
Synthetic data tools
The tools related to synthetic data are often developed to meet one of the following needs:
- Test data for software development and similar purposes
- Training data for machine learning models
We prepared a regularly updated, comprehensive sortable/filterable list of leading vendors in synthetic data generation software. Some common vendors that are working in this space include:
| Name | Founded | Status | Number of Employees |
|---|---|---|---|
| BizDataX | 2005 | Private | 51-200 |
| CA Technologies Datamaker | 1976 | Public | 10,001+ |
| CVEDIA | 2016 | Private | 11-50 |
| Deep Vision Data by Kinetic Vision | 1985 | Private | 51-200 |
| Delphix Test Data Management | 2008 | Private | 501-1000 |
| Genrocket | 2012 | Private | 11-50 |
| Hazy | 2017 | Private | 11-50 |
| Informatica Test Data Management Tool | 1993 | Private | 5,001-10,000 |
| Mostly AI | 2017 | Private | 11-50 |
| Neuromation | 2016 | Private | 11-50 |
| Solix EDMS | 2002 | Private | 201-500 |
| Supervisely | 2017 | Private | 2-10 |
| TwentyBN | 2015 | Private | 11-50 |
These tools are just a small representation of a growing market of tools and platforms related to the creation and usage of synthetic data. For the full list, please refer to our comprehensive list.
Synthetic data is a way to enable the processing of sensitive data or to create data for machine learning projects. To learn more about related topics on data, be sure to see our research on data.
If your company has access to sensitive data that could be used in building valuable machine learning models, we can help you identify partners who can build such models by relying on synthetic data:
If you want to learn more about custom AI solutions, feel free to read our whitepaper on the topic:
Also, you can follow our Linkedin page where we share how AI is impacting businesses and individuals, or our twitter account to learn more about the topic.
External Links
- 1. Koperniak, Stefanie (2017). “Artificial data give the same results as real data — without compromising privacy.” MIT. Revisited January 20, 2023.
- 2. Field, M. (2018). “Uber self-driving car saw but ignored pedestrian in deadly Arizona crash.” Telegraph. Revisited January 20, 2023.
- 3. Golson, J. (2016). “Google’s self-driving cars rack up 3 million simulated miles every day.” The verge.

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
AIMultiple Tabular Synthetic Data Benchmark Methodology in '24
Synthetic Data in Finance: Top 4 Applications in 2024
Synthetic Data Generation in 2024: Techniques & Best Practices

You wrote an excellent article.
I am currently doing research on synthetic data generation, I hope to publish my article soon.

Hello, Juan. We’re glad you enjoyed the article. And wish you the best in your publication. You can learn more about synthetic data here: https://research.aimultiple.com/category/data/synthetic-data/

Hi I would like you to study our requirements for sythentic datasets. and help us.

Would be good to see Mindtech Global in your list, as they are one of the leading suppliers of visual synthetic data, and the only provider with a complete end-end platfrom.

Hi Chris, thank you for the heads up! Could you please sign up @ https://grow.aimultiple.com so we can collect data on Mindtech Global and decide whether to feature it.
Thank you,

An excellent contribution !
Congrats 🙂

Very nice article. Simply and intelligibly written. All praise for the author.

Check out Simerse (https://www.simerse.com/), I think it’s relevant to this article. Cheers!

Hi everyone! I really enjoyed the article and wanted to share here this amazing open-source library for the creation of synthetic images. Flip allows generating thousands of 2D images from a small batch of objects and backgrounds.
https://github.com/LinkedAi/flip

The folks from https://synthesized.io/ wrote a blog post about these things here as well “Three Common Misconceptions about Synthetic and Anonymised Data”. https://blog.synthesized.io/2018/11/28/three-myths/. Perhaps worth citing.
Thanks for the suggestion!
Related research
Comments
Your email address will not be published. All fields are required.