An Assessment in 2024 For Why Chatbots Fail
We have previously touched on why your chatbot is likely to fail, how to make your chatbot a success, top chatbots and how many chatbots fail (a list that is constantly growing). Today, we will show you why it is hard for chatbots to hold human-like conversations, and why dealing with natural languages is hard.
Natural Languages are old and quite irregular
It is important to define the natural language concept as we begin. Natural languages are the product of thousands of years of speech patterns, evolved to fit the needs of a particular community at a particular time. They are very fluid, as there can be a lot of change over time (think Victorian English). Although we may attempt to catalog the different rules of natural languages, they eventually get replaced by new rules, and in some cases, they diverge so much that the new set of rules essentially become a new language.
One thing to keep in mind is that these rules are for the formal language. In casual text, we can expect to find a great deal of chaos: missing punctuation, missing capitalization, abbreviations, replacing letters with numbers, and so on. Worse still, some modifications are very uncommon (used by <1000 people), and would not make sense to the rest of the population.
We all want chatbots that can understand and give appropriate answers to the people it talks to. That, as we will see, is easier said than done.
Dealing with Natural Languages
Natural Language Processing (NLP) is a combination of Computer Science and Linguistics, that tries to make sense of text in a way that is useful to us. While the NLP methods have traditionally been rule-based, the field is now employing Machine Learning methods for many of the common Natural Language tasks, and chatbots are no exception.
An extreme case of the rule-based systems can be found on the chatbots that were developed before the Machine Learning craze of the past 5 or so years. Chatbots used to be, as described by our previous posts, handcoded FAQ services, presented in a conversational way. They were highly rigid in terms of what they could understand and what they could achieve. However, due to their simplicity, they would only say what you deemed appropriate. They would not learn inappropriate responses, because they could not learn.
As the chatbots get more complex and start being more lifelike, the one-size-fits-all approach starts not being viable. When choosing a chatbot vendor today, or implementing your own chatbot, it is important to make sure the chatbot you use will learn from its past experiences. Modern chatbots make use of the advancements in AI and Machine Learning in order to learn what your customers ask, and how they can better answer that.
Machine Learning & Data changed NLP
Machine Learning methods learn to make their own rules. They employ statistics to achieve a certain goal, which is generally finding rules that are true for as much of the data as possible. We can, of course, change those goals to better fit our needs.
A crucial part of every Machine Learning application is data. In many cases, having more data is beneficial. Sometimes, it may even be worth to spend your time acquiring more data than implementing better solutions.
The data in the case of chatbots and NLP is text, usually English. Chatbots learning English might seem simple at first, but what you have to keep in mind is that computers do not have an understanding of the world (a common sense) to understand the concepts presented in our sentences. As a species, we use hundreds of different words to describe an elephant, but we all share the rough concept of an elephant, no matter what we call it.

The bad news is, NLP is notoriously hard. There are many articles that explain why certain tasks are hard, and how they might be solved, and we would run out of space trying to explain why it is hard. Instead, we are going to give you a very high-level explanation of why NLP must be hard.
Why is NLP so hard?
1. Knowledge of the world is still difficult for computers to acquire
As humans, we can use our intuitions to make logical leaps, to understand what somebody is saying even if they do not explicitly tell us some of the information necessary to understand them. A computer does not have that kind of intuition, and it will never have unless it starts to experience life outside of the texts it has been provided with.
An artificial agent cannot know what an elephant is, even if you give it the whole dictionary: dictionaries try to define words with other words – when you don’t know any of the words, they are surprisingly ineffective. You have the necessary life experience to know the concept of an elephant, and how it can relate to other concepts that you know of, like walking and drinking.
What an artificial can know, however, is how likely it is for an elephant to move. Based on the text data available, it might know that the probability of an elephant moving is higher than a mountain moving. It might even learn that mountains are essentially huge rocks, and that small rocks can move. There can be a lot of knowledge gathered by an NLP system, but that will only be a small portion of the actual experience you have living on Earth. There are infinitely many things going on each second when you are near an elephant, and only a very small portion of it will ever be written.
The best we can do currently is to have word representations that make use of how words relate to each other:
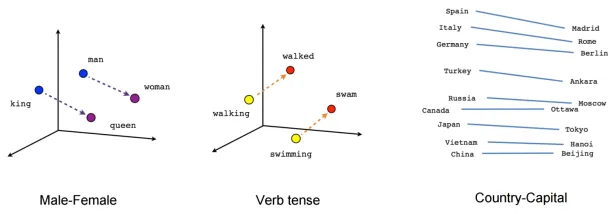
These representations make sure that the words that have similar uses are represented similarly. The most popular example is the way gender affects those representations: if we take the representation of the word king, remove from it the representation of man and add to it the representation of woman, we get a result that is very similar to the representation of queen.
2. It is hard to understand whether two sentences or two concepts are equal
For any given idea, we can write infinitely many sentences that roughly define the same idea. Unless what you are describing has a very specific definition, it is likely that the way you describe something is the first time somebody has defined it that exact way. This creates a problem for NLP applications, as they will never have enough data to cover all the ways in which things can be defined. No amount of data will solve this problem.
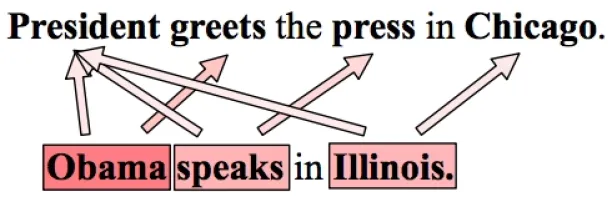
What they can do, however, is to find how different words in the sentence relate to each other, and how they together give meaning to the sentence. That way, if we replace a word in a sentence with a word with a similar representation, we end up with similar meaning for the sentence. This works fine if all we have are standalone sentences.
Chances are, we will have a much complicated structure that is made up of sentences. Paragraphs define a logical portion of the data that can be thought of being somewhat independent of the other paragraphs around it. In the state of the art models in NLP, we try to assign representations of paragraphs and use it as a context for the sentences in that paragraph. Of course, the actual context of that sentence has to do with the paragraphs before it, the paragraphs after it, the reasoning for why it was placed there and not anywhere else, and as we have discussed in the previous section, a whole lot of world knowledge.
3. Optimizing the wrong metrics
In Machine Learning research, we try to make models that generalize to as many problems as possible. That way, our research can benefit many people, and that is a great thing.
This notion, while great on paper, is one of the main reasons why your models do not perform as well as expected.
One of the key aspects of Machine Learning models is the objective (loss) function. That function defines what you are optimizing for, what the training wants to achieve. As we have mentioned before, these objective functions are generally very generic. They also have some mathematical properties to make sure that common learning algorithms work well with them.
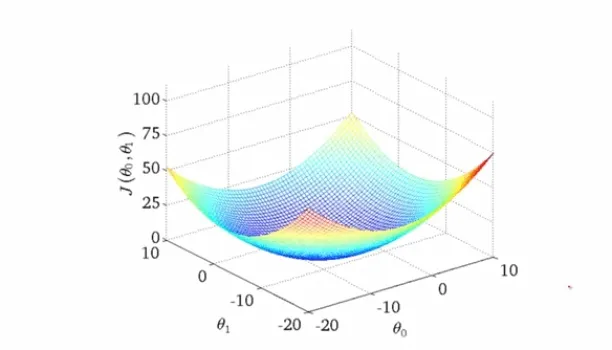
These functions differ from the actual metrics you get after you train your artificial agents, such as answer accuracy, the percentage of questions your bot can answer (both successfully and not), and click-through rate. Although you can sometimes construct objective functions that aim to optimize for some metric at the expense of others, these can only be verified after the training is done.
The main problem is that you usually cannot use the exact objective function you want. There are two reasons for this: either the function you want does not have the mathematical properties necessary to work well with the existing Machine Learning ecosystem, or it is very hard to train. The mathematical property we generally want to have is differentiability, though there are many others that are beyond the scope of this article. If your objective function is simply too hard to train, then you might be in luck, and it might just become possible in the next few years.
We, therefore, try to transform our problem into a more commonly used one. We might, for example, try to train a chatbot by optimizing it for guessing the next word in a sentence correctly, given the previous sentence and the current sentence. If we have a dataset of the correct answers to some questions, then this chatbot might very well learn to give the correct answers. However, if we grade it based on the percentage of correct answers, we may get surprising results. A chatbot that is very good at predicting the next word might struggle if the questions are given with a different phrasing than it has been trained on, producing grammatically correct but wrong answers.
An even bigger problem is that we don’t exactly know what metrics we want to optimize. It is great if we can have a chatbot that gives correct answers 99% of the time. But that does not say how it gives out those answers, and whether there is a trend in the remaining 1%. Here are some questions for you to consider:
- Would you prefer a chatbot that gets the answers right 99% of the time, but uses a very unprofessional language, or would you prefer one that gets the answers right 95% of the time, but uses formal English even if your customers ask their questions informally? What if we bring their accuracies down to 80% and 60%?
- Is it OK if your chatbot discriminates against a single person based on their accent or word choice? Is it OK if it discriminates against 100 people?
- Should your customers all get the same chatbot that answers with 70% accuracy, or should a select group get %90 accuracy at the expense of the others?
- Do you want your minimum customer satisfaction to be the highest, or the average satisfaction?
There are obviously no right answers to these questions. It depends on the company, it depends on the service, it depends on the customers. In the end, we have to choose carefully what chatbot metrics need to be tracked. Some of them will be difficult to put in numbers. We will now look at how we can spot such biases in data, and what we can do to prevent them.
The human bias
As we are dealing with natural languages, the data you use is ultimately generated by humans. Since it is hard to gather a lot of data, we prefer to use representations of words that have been previously computed using large datasets, and use our own data to fine-tune those representations. Common choices include Wikipedia, Twitter, Common Crawl (most frequently visited websites), and Google News.
The feedback you get from the people who respond to your chatbot is especially important. The way people interact with your chatbot will be unique to your chatbot, and your chatbot needs to be good at answering the specific questions of your users. While you cannot directly know how good your chatbot is at forming responses, you know that the human responses are gold standard. That is, of course, until they aren’t.
The thing you have to keep in mind is that your chatbot will carry the characteristics of the underlying text data. That is generally desirable, as it makes your chatbot more human-like, but your chatbot also adopts the biases (large and small) that the people who wrote parts of your data carry. And that is when you have to ask yourself: how human-like do I want my chatbot to be?
Common crawl: A case study
Rob Speer, co-founder of Luminoso, recently published an article on how the Common Crawl data can lead to racist behavior. He illustrates it by using sentiment classification, a common task in Natural Language Processing that aims to assign positive or negative sentiments to words and sentences. Given a list of positive and negative words, he trains an artificial agent that learns to classify sentences into these two categories.
The results reveal some unfortunate truths: the sentence “Let’s go get Italian food” is classified as more positive than “Let’s go get Mexican food”, even though they are functionally the same. A more horrifying bias exists for names, where a seemingly neutral sentence “My name is Emily” is classified as positive, while “My name is Shaniqua” is classified as negative. As he points out, the more stereotypically white a name is, the more positive its sentiment.
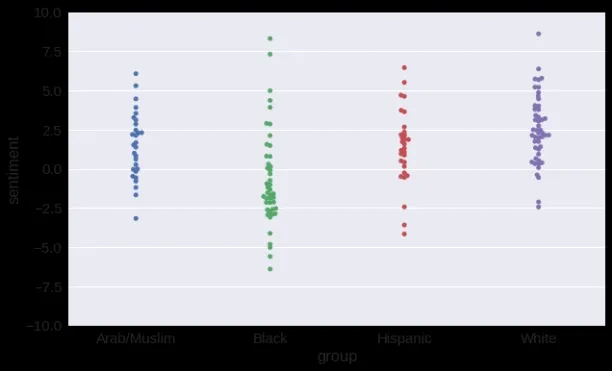
Each and every dot in the above graph represents how positive a name that stereotypically belongs to that group is. We can see that names in the white group are, on average, perceived as more positive. Even if your chatbot does not specifically calculate the sentiment of your sentences, the underlying patterns that cause this issue are still in your data.
Rob also notes in a following post that Perspective API, created by Google’s Jigsaw team in an attempt to “improve conversations online”, has a model to evaluate how toxic a sentence is, which has the same racist biases. The fact that Jigsaw’s aim is to use technology to “make people in the world safer” only adds insult to the injury.
Combating human biases
Research is done in an attempt to stop artificial agents from acquiring “dangerous” biases like racism and sexism. Although it is up to you to decide on which biases are dangerous and which biases are not, these are the baby steps the researchers are taking, and we will hopefully start hearing less chatbot fails.
In the meanwhile, you can try to improve the quality of the data your chatbot is working with. The chatbot fails that we have seen so many of are all caused by letting chatbots use all of the data they can get. There inevitably will be some people who have fun saying obscenities to your chatbot, and you should not use that as your data. Manually filtering the data so that only the high quality conversations are used will take time, energy, and money, but it may save you from a scandal.
If you are currently using a chatbot, you should also contact your chatbot vendor. See what they are doing to stop their chatbots from learning racist and sexist remarks, or if they even know how such things occur. If you are a vendor, understanding the problem and researching ways to avoid it is definitely worth your time. We provide a detailed guide on AI biases and how we can reduce them, feel free to read it.
Keep these in mind, and make sure you help your customers when your chatbot falls short. We are not yet at a point where you can let chatbots run wild without complications. Accepting that is the first step in making your chatbot a success.
Now that you know more about potential issues about chatbots, it might be good time to understand their huge benefits.
And if you believe your business would benefit from adopting conversational AI technology, you can view our comprehensive and data-driven list of chatbot platforms and chatbot agencies.
And you still have questions on chatbots, we would like to help:

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
8 Restaurant Chatbots in 2024: 5 Use Cases & Best Practices
Top 4 Chatbot Sentiment Analysis Benefits in 2024
Travel Chatbots in 2024: Top 8 Use Cases, Examples & Benefits
Related research
Conversational Banking: Everything You Need to Know in 2024
Comments
Your email address will not be published. All fields are required.