What is Data Augmentation? Techniques & Examples in 2024
The performance of most ML models, and deep learning models in particular, depends on the quality, quantity and relevancy of training data. However, insufficient data is one of the most common challenges in implementing machine learning in the enterprise. This is because collecting such data can be costly and time-consuming in many cases.
Companies can leverage data augmentation to reduce reliance on training data collection and preparation and to build more accurate machine learning models faster.
What is data augmentation?
Data augmentation is a set of techniques to artificially increase the amount of data by generating new data points from existing data. This includes making small changes to data or using deep learning models to generate new data points.
Why is it important now?
Machine learning applications especially in the deep learning domain continue to diversify and increase rapidly. Data-centric approaches to model development such as data augmentation techniques can be a good tool against challenges that the artificial intelligence world faces.
Data augmentation is useful to improve the performance and outcomes of machine learning models by forming new and different examples to train datasets. If the dataset in a machine learning model is rich and sufficient, the model performs better and more accurately.
For machine learning models, collecting and labeling data can be exhausting and costly processes. Transformations in datasets by using data augmentation techniques allow companies to reduce these operational costs.
One of the steps in a data model is cleaning data which is necessary for high-accuracy models. However, if cleaning reduces the representability of data, then the model cannot provide good predictions for real-world inputs. Data augmentation techniques can enable machine learning models to be more robust by creating variations that the model may see in the real world.
You can also check our article on the benefits of data augmentation for deep learning models.
How does it work?
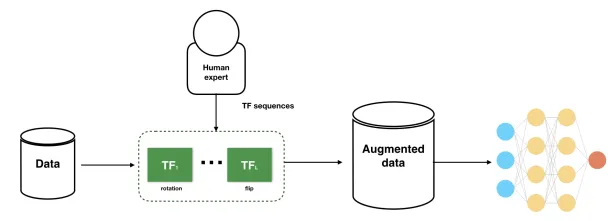
For image classification and segmentation
For data augmentation, making simple alterations on visual data is popular. In addition, generative adversarial networks (GANs) are used to create new synthetic data. Classic image processing activities for data augmentation are:
- padding
- random rotating
- re-scaling,
- vertical and horizontal flipping
- translation ( image is moved along X, Y direction)
- cropping
- zooming
- darkening & brightening/color modification
- grayscaling
- changing contrast
- adding noise
- random erasing

Advanced models for data augmentation are
- Adversarial training/Adversarial machine learning: It generates adversarial examples which disrupt a machine learning model and injects them into a dataset to train.
- Generative adversarial networks (GANs): GAN algorithms can learn patterns from input datasets and automatically create new examples which resemble training data.
- Neural style transfer: Neural style transfer models can blend content image and style image and separate style from content.
- Reinforcement learning: Reinforcement learning models train software agents to attain their goals and make decisions in a virtual environment.
Popular open source python packages for data augmentation in computer vision are Keras ImageDataGenerator, Skimage and OpeCV.
For natural language processing (NLP)
Data augmentation is not as popular in the NLP domain as in the computer vision domain. Augmenting text data is difficult, due to the complexity of a language. Common methods for data augmentation in NLP are:
- Easy Data Augmentation (EDA) operations: synonym replacement, word insertion, word swap and word deletion
- Back translation: re-translating text from the target language back to its original language
- Contextualized word embeddings
How is it different from synthetic data?
Generating synthetic data is one way to augment data. There are other approaches (e.g. making minimal changes to existing data to create new data) for data augmentation as outlined above.
Feel free to check our article on synthetic data for computer vision.
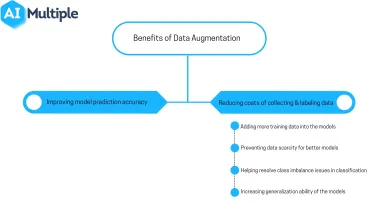
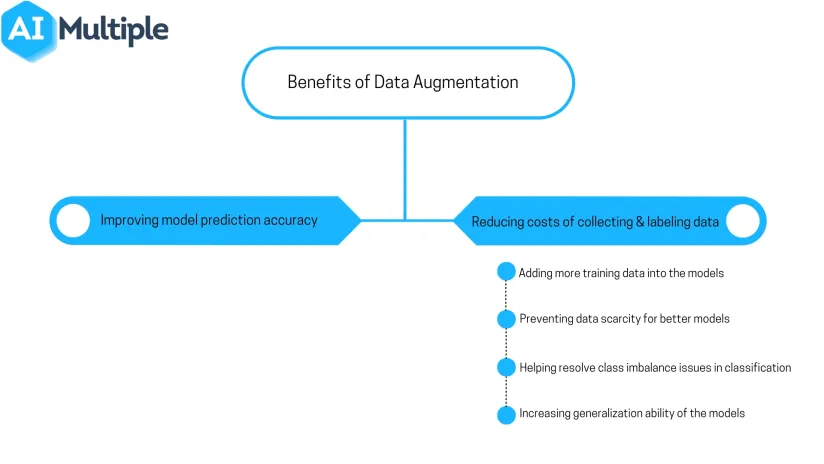
What are the benefits of data augmentation?
Benefits of data augmentation include:
- Improving model prediction accuracy
- adding more training data into the models
- preventing data scarcity for better models
- reducing data overfitting ( i.e. an error in statistics, it means a function corresponds too closely to a limited set of data points) and creating variability in data
- increasing generalization ability of the models
- helping resolve class imbalance issues in classification
- Reducing costs of collecting and labeling data
- Enables rare event prediction
- Prevents data privacy problems
What are the challenges of data augmentation?
- Companies need to build evaluation systems for the quality of augmented datasets. As use of data augmentation methods increases, assessment of quality of their output will be required.
- Data augmentation domain needs to develop new research and studies to create new/synthetic data with advanced applications. For example, generation of high-resolution images by using GANs can be challenging.
- If a real dataset contains biases, data augmented from it will contain biases, too. So, identification of optimal data augmentation strategy is important.
What are use cases/examples in data augmentation?
Image recognition and NLP models generally use data augmentation methods. Also, the medical imaging domain utilizes data augmentation to apply transformations on images and create diversity into the datasets. The reasons of data augmentation interest in healthcare are
- Small dataset for medical images
- Sharing data is not easy due to patient data privacy regulations
- There are only a few patients whose data can be used as training data in the diagnosis of rare diseases
Example studies in this field include:
- Brain tumor segmentation
- Differential data augmentation for medical imaging
- An automated data augmentation method for synthesizing labeled medical images
- Semi-supervised task-driven data augmentation for medical image segmentation
If you are ready to use data augmentation in your firm, we prepared data driven lists of companies that offer solutions in this area. However, these lists are not just focused on companies providing data augmentation functionality, most of the time, this functionality is provided as part of more comprehensive software packages (i.e. deep learning software):
If you need help in choosing vendors who can help you get started, let us know:
This article was drafted by former AIMultiple industry analyst Ayşegül Takımoğlu.

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow on
Comments
Your email address will not be published. All fields are required.