Data Mining: What is it & Why do businesses need it in 2024?
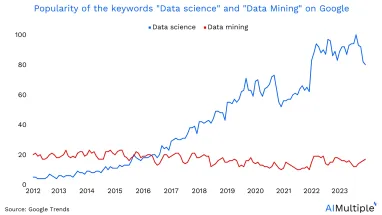
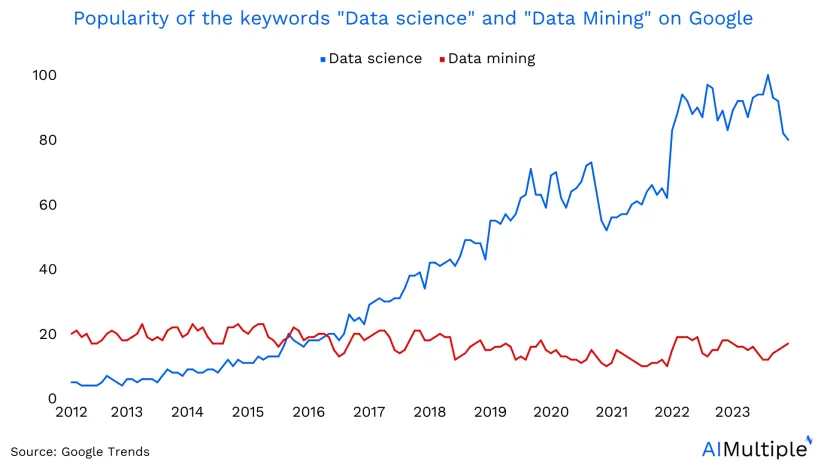
The total volume of data created worldwide is expected to reach 149 zettabytes by 2045. The significant increase in data size is driving a growing interest in big data and data mining (former version of data science) as more businesses are trying to leverage this data to improve their customer relations, optimize marketing campaigns, predict sales, etc.
What is data mining?
Data mining, also known as knowledge discovery in data (KDD), is the process of discovering patterns and correlations within big datasets to predict outcomes. Companies utilize data mining to convert raw data into insightful information. Businesses employ data mining techniques to discover areas of improvement to increase revenues, cut costs, improve customer relationships and reduce risks.
What is the origin of data mining?
The term data mining was used in the 1990s for the first time as the official name for finding patterns in large datasets. In the 2010s, “data science” gained popularity and started to replace “data mining” as a term (see the figure above). For example, the section on Statistical Learning and Data Mining in the American Statistical Association changed its title to the Section on Statistical Learning and Data Science.
Data mining is connected to classical statistics and artificial intelligence (AI) & machine learning (ML).
Classical statistics
Data mining is built on statistical models which analyze data and data connections: Some of these models include:
- Regression analysis
- Standard deviation
- Standard distribution
- Standard variance
- Discriminatory analysis
- Cluster analysis
- Confidence intervals
Artificial intelligence & machine learning
Unlike statistics, artificial intelligence (AI) and machine learning are based on simulating human approaches to solve problems. In AI and ML, machines are given sets of training data to learn from in order to generate answers that are not explicitly programmed into the algorithm. AI and ML algorithms adapt to new inputs and replicate human tasks by exploring new data.
What are the data mining techniques?
The data mining techniques are vital to optimize data quality, and they include:
- Data cleaning and preparation: Raw data is cleaned and converted to designated formats in order to be further analyzed.
- Tracking patterns: At this stage, the trends and patterns are identified (can be done manually via applying statistical models and tests or via machine learning algorithms such as pattern recognition algorithms) in data to obtain inferences about business outcomes.
- Classification: Classification is the process of identifying specific features or attributes which associate with different types of data in order to categorize or classify it. For instance, classification can be used to categorize personally identifiable information (PII), by recognizing that it is a name or gender, to protect or mask it in business operations.
- Association: Association is the practice of understanding and concluding that certain events in data happen in correlation, but not necessarily cause one another.
- Outlier detection: Outlier detection determines any anomalies in datasets. Outliers affect the generalization of the model, however, they can be important clues to optimize business strategies (e.g. product sales peak in certain periods).
- Clustering: Clustering is the practice of dividing data points into a number of groups or clusters based on similarities and features.
- Regression: Regression algorithms reveal the strength of relationship between variables in a dataset, for example, a company employs regression analysis to measure the impact of marketing channels on its sales. The variables are “sales” being a dependent variable, and “three marketing channels” (social media, news and Youtube) as the independent variables which sales would depend on. Regression is applicable for forecasting and data modeling.
- Prediction: Predictive analytics analyze current or historical data in order to recognize trends and predict future events.
- Sequential patterns: Sequential patterns provide insights about series of events taking place in sequences. For example, retailers can leverage sequential patterns to discover the types of items a customer will buy after buying a pair of shoes, and recommend these items accordingly.
- Decision trees: Decision trees are a type of classification algorithm which provide details about relationships between data variables in a tree-like model. For example, a manufacturing firm decides between two products to develop. They have three different investment plans for each product. In such complex decision process, decision trees allow businesses view each investment plan for every product as a separate branch. Businesses will view for both products three investment plan branches and evaluate the optimal result by choosing among these six branches.
- Visualization: Organizations can employ dashboards and visualizations on different metrics to highlight patterns in data visually.
- Neural networks: Neural networks are a type of machine learning model used in deep learning. NNs typically produce more accurate results, but tend to be less straightforward in the way they generate these results.
- Long-term memory processing: It is the capacity to investigate data over extended periods.
- Advanced artificial intelligence: Some advanced AI deployments such as computer vision, speech recognition, or sophisticated text analytics using Natural Language Processing (NL) are applied in data mining in order to extract insights from semi-structured or unstructured data.
What are the data sources used in data mining?
Some of the data sources include:
- Flat Files: They are data files in text form or binary and represented by data dictionary (e.g: CSV file).
- Relational Databases: The data that is organized in tables with rows and columns are relational databases, represented in SQL.
- Data Warehouse: The warehouses are integrated data derived from multiple sources. There are three types of data warehouse:
- Enterprise warehouse is the collection of company business data and information about its customers.
- Data mart warehouse is a smaller subset of the broader data warehouse with a focus on a business line or department (e.g: finance or marketing).
- Virtual warehouse is a business database copying from multiple sources throughout a production system to provide a comprehensive view of assets and materials.
- Transactional Databases: These data are organized by time stamps and date to represent transaction in databases.
- Multimedia Databases: These databases consists audio, video, images and text media
- Spatial Databases: They contains geographical information.
- Time Series Databases: These databases contains information varying across time. Some examples are stock exchange data and user logged activities.
- Online resources : These are documents and resources (e.g: audio, video and text) which are identified by Uniform Resource Locators (URLs). These are web resources, linked by HTML pages, and accessible via the Internet network. This data can be collected using web crawlers to automatically extract this data and send it to users for further manipulation or analysis.
How does data mining process work?
Data mining processes include three main steps:
- Data collection: Organizations collect data and load it into their data warehouses.
- Data storage and management: They store and manage the data, either on in-house servers or the cloud. Business analysts, management teams, and IT professionals determine how to store and organize the data according to its size, relevance to business departments, or sensitivity.
- Data preparation: At this stage, the data quality problems are resolved. Duplicate, missing, or corrupted data are cleaned to provide appropriate data for further analysis.
- Data modeling: The algorithms to determine patterns are applied to the data.
- Model testing: It is an iterative phase to find the best fitting algorithm for the data by examining the accuracy of the results delivered by a particular model.
- Result presentation: At this stage, the data and findings are presented in an easy format (e.g. graphs or tables).

What are the benefits of data mining?
Data mining benefits include:
- Analyzing big data in a fast and accurate manner
- Predicting behaviors and trends, and discovering hidden patterns
- Ensuring data-driven decisions
- Generating efficient, cost-effective solutions
- Helping businesses make profitable production and operational adjustments
- Detecting credit risks and fraud, building risk models, and improving product safety
What are the disadvantages of data mining?
- The complexity of the tools: The data mining tools are complex and challenging to use, requiring high levels of training to use them effectively. These tools work with varying types of data, so finding the correct tool can be challenging.
- Accuracy: There is always risk concerning information accuracy. The risks increase if the data lacks diversity causing bias in the results.
- Privacy concerns and data security: There are always privacy concerns since the team in charge of data might share customer data with competitive businesses or organizations for individual purposes. Businesses can leverage privacy enhancing technologies, such as masking, homomorphic encryption, or zero knowledge proof, to protect sensitive data.
Who are the main users of data mining?
Telecom, Media & Technology
Telecom, media, and technology companies apply analytic models to customers’ data to predict customer behavior and offer targeted and relevant campaigns.
Retail and eCommerce
Retail companies and eCommerce platforms apply data mining to uncover customer insights from the big data they have in order to improve customer relations, optimize their marketing campaigns, and predict sales with data models.
Banking
Data mining assists financial services companies in viewing market risks, exposing fraud faster, managing regulatory compliance obligations, and obtaining optimal returns on their marketing investments.
Manufacturing
With data mining and manufacturing analytics, manufacturers predict the waste in production assets, anticipate maintenance, maximize uptime, and keep the production line on schedule.
Insurance
Insurance companies benefit from data mining techniques and price scraping to price their products effectively and develop new offers of competitive products to their target prospects. They can solve problems regarding fraud, compliance, risk management, and customer churn with these techniques.
To discover more how data mining is applied in businesses, feel free to read our articles:
- Data Mining in Business Intelligence: The Ultimate Guide
- An Ultimate Guide to Data Mining in Business Analytics
If you believe your business will benefit from data solutions, you can check our comprehensive software and tools lists.
And we can help you find the right vendor:

Next to Read
Web Scraping vs Data Mining: Why the Confusion? in 2024
How to Apply Data Mining in Business Analytics in '24
How to Pair Data Mining & Business Intelligence in '24?
Related research
SAP Process mining: Top 3 use cases & case studies in 2024
Comments
Your email address will not be published. All fields are required.